
Alphanet
ALPHABETS ONLY
Version: releasing soon
Deep dive into the underlying machine learning models and experiments powering our translation engine.
Leveraging MediaPipe's powerful landmark detection capabilities, this model achieves an impressive 99% testing accuracy across 6 distinct actions. The model supports basic conversational signs including 'hello', 'how are you', 'sorry', 'welcome', and 'thank you'.
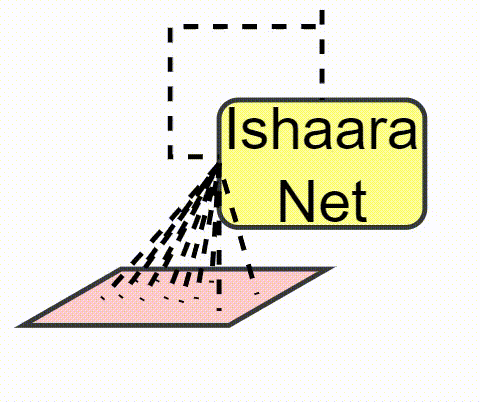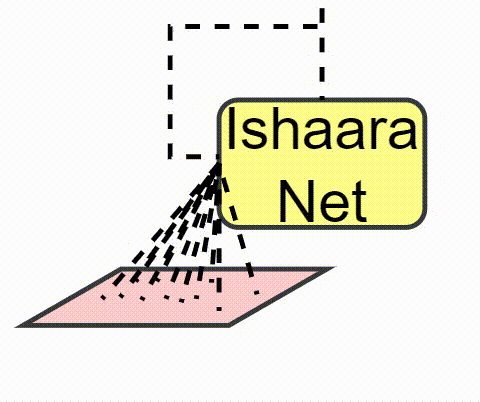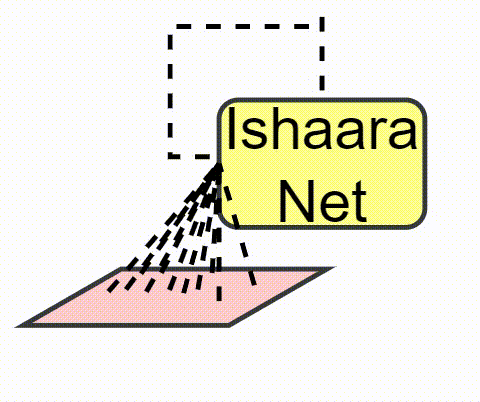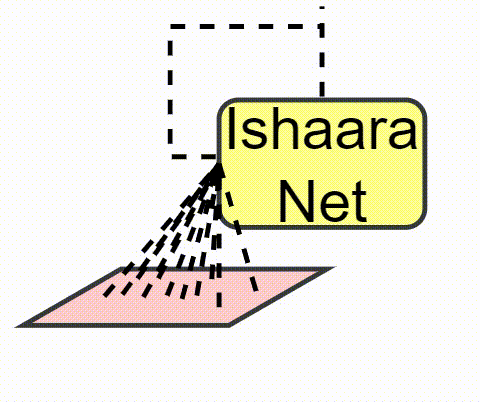
A sophisticated hybrid approach combining Convolutional layers with LSTM cells for advanced video classification. This model represents a perfect balance between spatial and temporal feature extraction, trained extensively on our custom ISL dataset.
An ambitious implementation utilizing 3D convolutions for comprehensive spatio-temporal feature learning. While currently limited by hardware constraints, this model represents our ultimate vision for future high-fidelity ISL development.

